Many explanations of JOIN are wrong, and people get confused

Update [2025-12-28]: there is now a much more comprehensive “A modern guide to SQL JOINs” that covers this topic in more detail. The original post is left as a historical archive.
Let’s google “how left join works” and see what the first few results tell us.
W3schools.com (the top snippet): “The LEFT JOIN command returns all rows from the left table, and the matching rows from the right table.”
Learnsql.com: “LEFT JOIN, [...] returns all records from the left (first) table and the matched records from the right (second) table.”
TutorialsPoint.com: “Left (Outer) Join: Retrieves all the records from the first table, Matching records from the second table and NULL values in the unmatched rows.”
Intellipaat.com: “LEFT JOIN is a keyword used to select all rows from the left table and the matched values between the two tables.”
Sqltutorial.com: “The left join, however, returns all rows from the left table whether or not there is a matching row in the right table.”
Let’s ask ChatGPT 4: “Result: The result set will include:
All rows from the left table.
The matched rows from the right table.
If there is no match, the result is still a row with the left table's data, but the right table's corresponding columns will contain NULL.“
There are many more. What’s common for all those summaries is that they are all wrong. Okay, they are right only for one commonly used type of ON condition: ID equality (we’ll discuss it below).
If you use those search results to actually learn about LEFT JOIN, here is what will happen:
your mental model will mostly work, but
sometimes it will break unexpectedly, and
you won’t know why.
I now remember a few times when that happened to me, years ago: I changed the query slightly, the results were completely unexpected, and I did not understand what was going on.
Let’s try and fix it.
The common explanations are mostly right
The common explanations are right if and only if you use the following ON condition:
> SELECT …
> FROM tbl_a LEFT JOIN tbl_b
> ON tbl_a.id = tbl_b.id
And nothing else. That is:
you compare two IDs by equality.
The ID in the second table must be a primary key (or at least have a unique index).
The ID in the first table may or may not be unique.
Any deviation from this formula (if I’m not mistaken here) triggers the generalized behavior of JOIN that is NOT covered by the common explanations.
Here is an example from a recent confused post on Reddit:> FROM R LEFT JOIN S ON r.id = s.id AND r.col2 > condition
Because of the “AND r.col2 > condition” fragment, this triggers the generalized behavior and breaks OPs mental model, as expected.
The common explanations should have been right (but we can’t have nice things)
Having said that, I really think that JOINs should really only work in a restricted way, like explained above. Your SQL server should only let you write SQL using ID equality, and disallow any other forms of ON condition.
Why?
First, because it is what you actually use in most cases anyway!
Second, the restricted case has very good, very simple mental model.
Third, the restricted case is very optimizer-friendly and thus performant.
The generalized behavior of JOIN really should have been a separate operator, something like ALGEBRAIC JOIN (or some other uncommon word). Unfortunately, we’re stuck with 45+ years of accumulated old growth, and the general behavior of JOIN is a default that you cannot even disable.
We can’t have nice things.
Making sense of generalized LEFT JOIN behavior
The formula in the “ON …” clause is commonly called “ON condition”. But let’s call it a “match function” from now on. Maybe this particular choice of words would help with understanding the generalized behavior specifically.
Now, let’s try to write down how the LEFT JOIN actually works in the generalized case, and then we’ll test some unusual match functions.
Generalized LEFT JOIN algorithm
For each row of the first table we do the following:
For each row of the second table we call the match function. If it returns true, we add a row to the output. Data from all columns of both tables is available for output.
If the match function has never returned true, we add one row to the output. But here only the data from the left table is available for output; data from the right table is not available, and
NULLvalues are used instead.
End.
This, I think is what they should have told you.
Things to note:
This algorithm uses a nested loop. Once again: “for each row of the first table we process each row of the second table”. For example, if we have 3 rows in the first table, and 5 rows in the second table, we’ll call the match function 15 times.
The “never returned true” is a careful choice of words. It works even if the second table is empty.
Sample dataset
Let’s build two very simple single-column tables: t_a and t_b. Here is the schema and initial data used in this post: https://gist.github.com/squadette/7024e75262932e0b44171f5ad939529f.
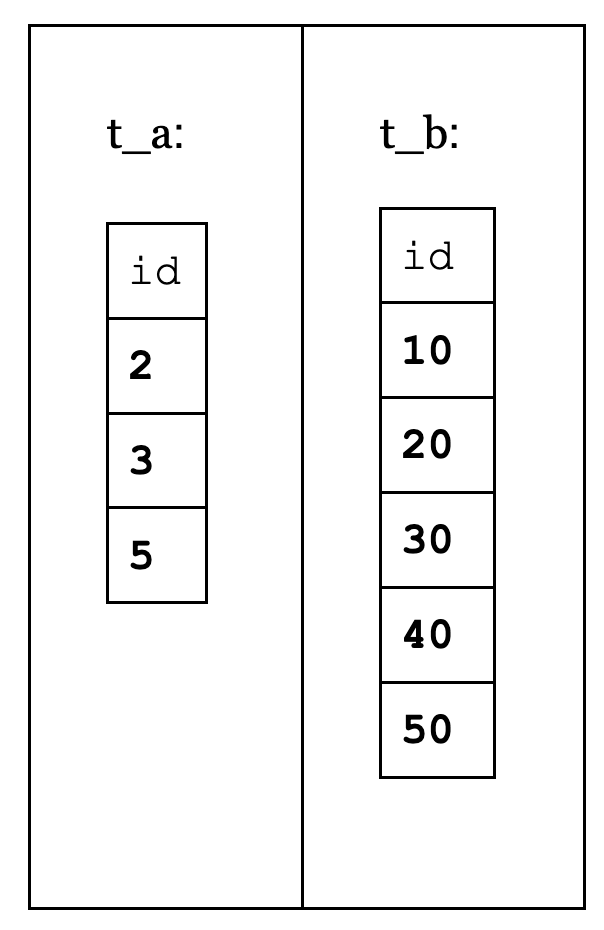
t_a has three rows ((2), (3), (5)).t_b has five rows ((10), (20), (30), (40), (50)).
Trivial match function #1: “always true”
Behold the following query:
SELECT t_a.id, t_b.id
FROM t_a LEFT JOIN t_b ON 1 = 1
Note the unusual matching function, ON 1=1. It always returns true, and does not even take into account the data values. What does it mean? Let’s trace the algorithm.
Take the first row of the first table (2). For each row of the second table (each of the 10, 20, 30, 40, 50), we call the match function. The match function returns true every time, and so we add a row to the result set. All the data is available. So, we have the following intermediate result:

(This is after processing the first row of the first table.)
Now, let’s process the second row (3). Again, for each row of the second table (we reprocess the second table each time!) we call the match function. The match function returns true every time, and so we add a row to the result set. Five more rows added in total.
Finally, after we process the third row of the left table (5), we’ve again added five more rows to the result set.
So, we have 15 rows in the output:
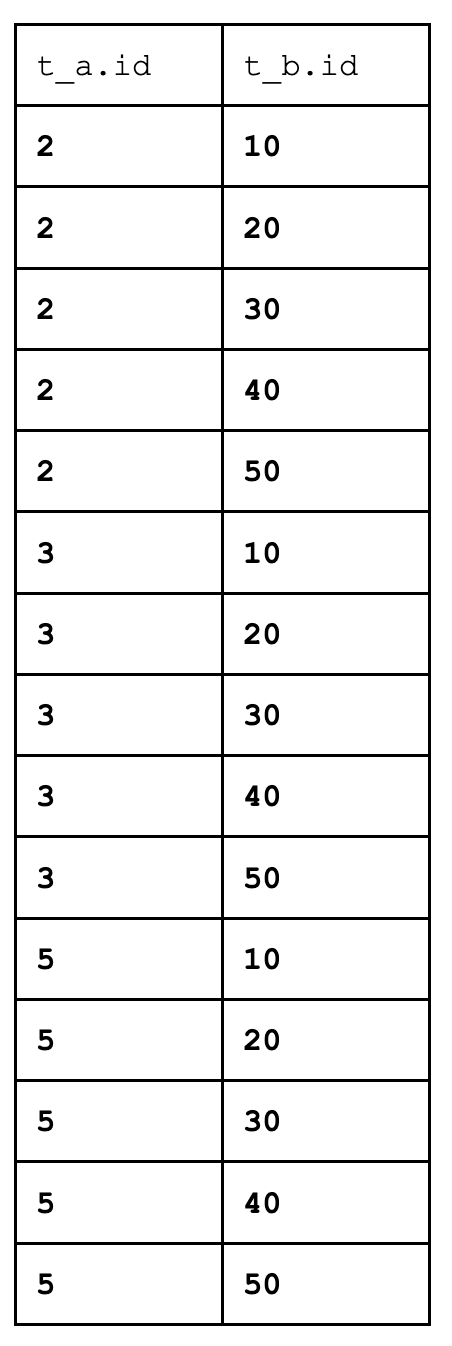
We can now go back to the beginning of this post, re-read the explanations, and see how wrong they are. Here, the result contains not just “all rows”, but “all rows, several times over”.
Trivial match function #2: “always false”
Now let’s consider another query:
SELECT t_a.id, t_b.id
FROM t_a LEFT JOIN t_b ON 1 = 0
Note another unusual matching function, ON 1=0. It always returns false, and does not even take into account the data values. What does it mean? Let’s trace the algorithm.
Take the first row of the first table (2). For each row of the second table (each of the 10, 20, 30, 40, 50), we call the match function. The match function returns false every time, and so we cannot add a row. After we processed all rows of the second table, the match function has never returned true. That is, we must add a single row to the intermediate result:
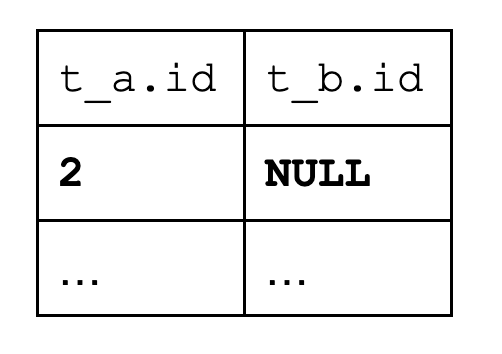
(This is after processing the first row of the first table.) The data from the left table is available, the data from the second table is not, and so NULL is used instead.
Now, let’s process the second row (3). Again, for each row of the second table (we reprocess the second table each time!) we call the match function. The match function returns false every time. At the end, we add one more row to the result set.
Finally, after we process the third row of the left table (5), we again add one row to the result set.
So, we have 3 rows in the output:
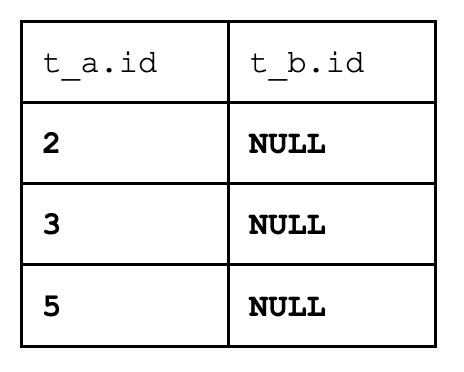
Now this output seemingly matches the explanations from the beginning of this post. “All rows from the first table, with NULL values from non-matching rows”, or something like that. We declared that none of the rows should match, and they didn’t.
Confusing matching function: pseudo-WHERE
The following example allows us to show where people get actually confused.
SELECT t_a.id, t_b.id
FROM t_a LEFT JOIN t_b ON t_a.id = 2;
As a matching function, we used something that looks like a normal condition. You could have used it in any WHERE clause:
SELECT t_a.id
FROM t_a
WHERE t_a.id = 2
And it would have been a nice simple SQL query, straight from the textbook.
But we used it as a matching function. And we triggered a generalized LEFT JOIN behavior. And we’ll be cognitively punished.
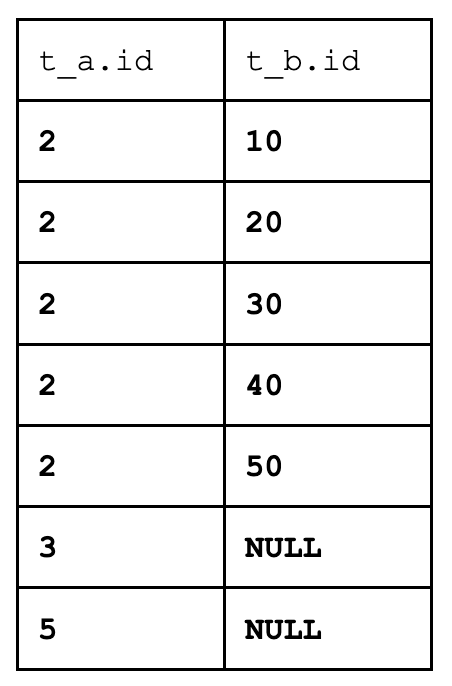
We get seven rows. Five with t_a.id = 2, one with t_a.id = 3, and one with t_a.id = 5.
Let’s trace the algorithm:
Take the first row of the first table (2). For each row of the second table (each of the 10, 20, 30, 40, 50), we call the match function. The match function returns true every time because t_a.id = 2, and so we add a row to the result set. All data is available. We add five rows.
Now, let’s process the second row (3). Again, for each row of the second table we call the match function. Now the match function returns false every time, and so we need to add one row to the result set.
Finally, after we similarly process the third row of the left table (5), we again add one row to the result set.
This, I think, is how people get confused if they accidentally use a generalized LEFT JOIN. The condition in the “ON” clause and the condition in the “WHERE” clause are two different things, even though they look the same.
Did you mean?
If you accidentally wrote the query from the previous section, what you probably meant was:
SELECT t_a.id, t_b.id
FROM t_a LEFT JOIN t_b ON t_a.id = t_b.id
WHERE t_a.id = 2;
We changed the ON clause to use the restricted ID equality. Also, we moved the condition to where it belongs: to the WHERE clause.
We can now also guess what the Reddit poster most probably meant:
> FROM R LEFT JOIN S ON r.id = s.id
> WHERE r.col2 > condition
Again, we restricted the ON clause and moved the filtering to WHERE.
Conclusion
We saw that common explanations of LEFT JOIN only describe a restricted case of its usage. If you deviate from that restriction, the full algorithm kicks. If you learned this on your own, the full algorithm will break your mental model and you would be confused.
You can and should, however, use only restricted case. But you must also be prepared for the fact that, apparently, Internet may provide you with misleading information.
In the follow-up post, we’ll see:
how the restricted case is optimized;
how the generalized algorithm is counter-intuitive, and maybe not even needed;
how the generalized behavior is full-table scan, squared;
what’s the deal with
INNER JOIN.